Editor reference
Alle editorvelden, filemanageracties, validatieregels en codecontract.
Open editor reference →Execution engine
Elements zijn Python bouwblokken binnen Dashview. Deze hub splitst de documentatie in twee detailreferenties: editor/filebeheer en runtime/execution.
logger.info(...), logger.error(...) en logger.exception(...) gebruiken om diagnostische meldingen aan die logs toe te voegen.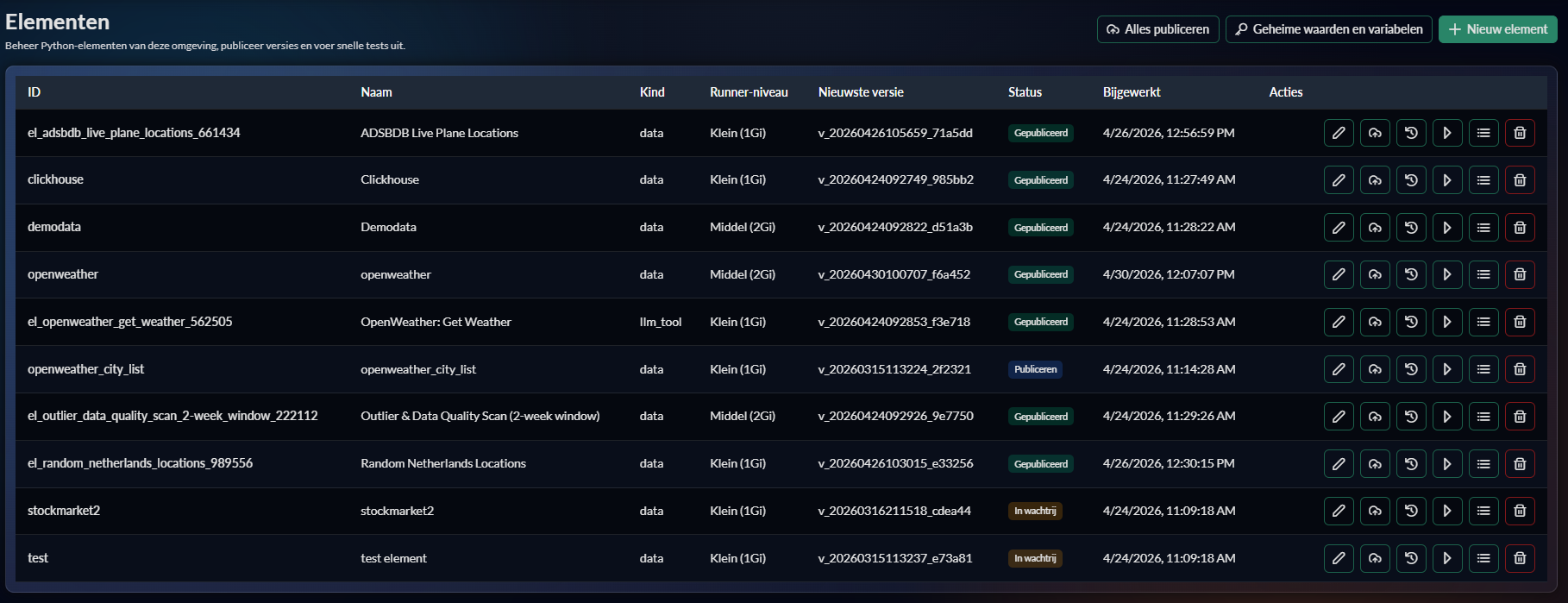
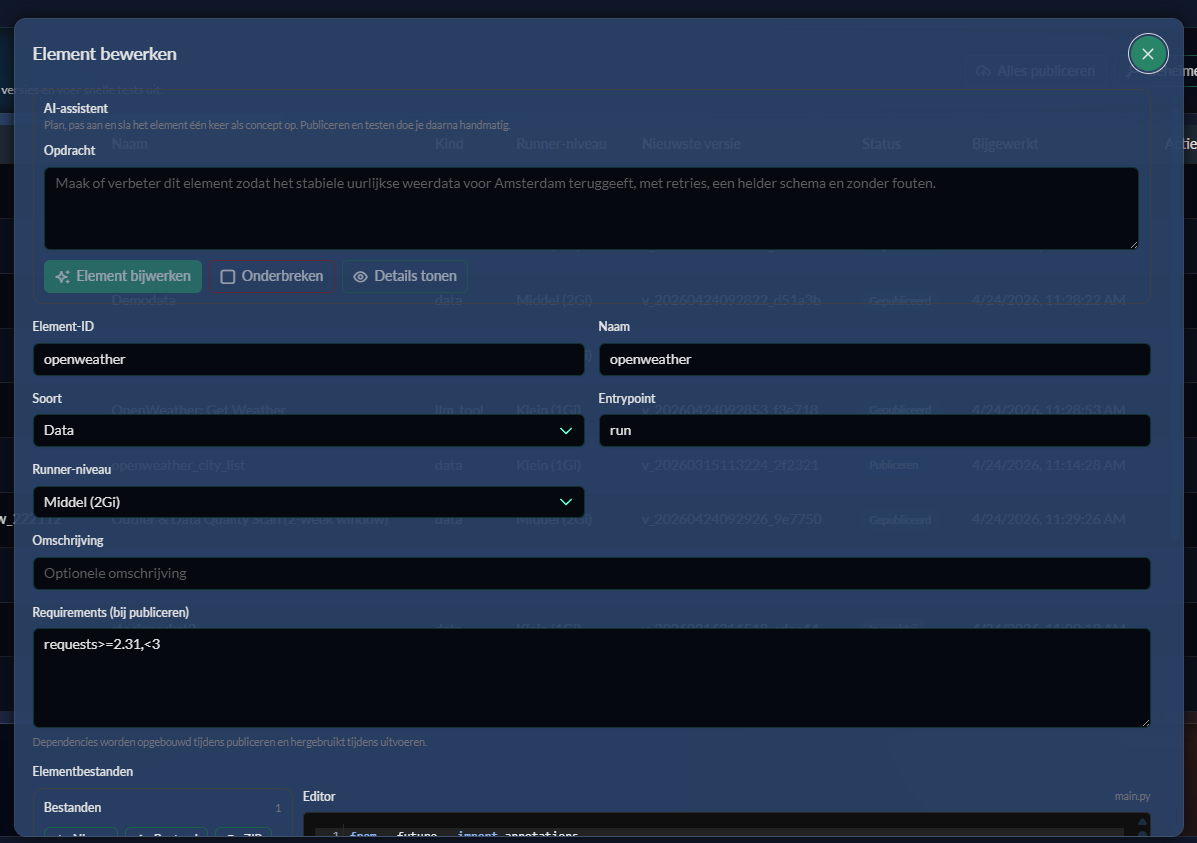
main.py; splits modules zodra logica groeit.Gebruik het veld Groep om Elements binnen je tenant visueel te ordenen. Groepen helpen beheerders om Elements sneller terug te vinden wanneer de lijst groeit.
Finance, Operations of Experimenten.Alle editorvelden, filemanageracties, validatieregels en codecontract.
Open editor reference →Publish/versioning, runtime vars/secrets, test execute payloads en logvelden.
Open runtime reference →element om een element als querybare bron te draaien.transform/transforms met type: "element" om rows door een element te laten lopen.elementParams en request param mapping voor dynamische input.def run(params):.element en kies het gepubliceerde Element.elementParams, bijvoorbeeld een default country of limit.allowedRequestParams om expliciet te bepalen welke filterkeys naar het Element mogen.requestParamMap als de dashboardfilter anders heet dan de param die je Element verwacht.params, bijvoorbeeld params.get("country").def run(params):
country = params.get("country", "NL")
limit = int(params.get("limit", 10))
rows = load_sales_rows(country=country, limit=limit)
return [{
"country": row["country"],
"customer": row["customer"],
"revenue": row["revenue"],
} for row in rows]
Voorbeeldflow: dashboardfilter country → Element-datasource request param
country → params.get("country") in het Element → widget rendert de nieuwe rows.
paramsparams.rows: inputdataset van de huidige transformstap.params.transformParams: transformconfig uit de datasource.context: tenant/element/version metadata.yield alleen als het Element rows incrementeel produceert; mix dat niet met een return value.(rows, info) teruggeeft, return je alleen rows.def run(params):
rows = params.get("rows") or []
transform_params = params.get("transformParams") or {}
result = predict_session_pattern_trend(rows, transform_params)
if isinstance(result, tuple) and len(result) == 2:
return result[0] # alleen rows teruggeven
return resultqueryDataSourcestableName-aliassen als tabelnamen in SQL.orders of orders_prod.tableName alias meegeeft.def run(params):
result = queryDataSources("""
select customer, revenue
from orders
order by revenue desc
limit 100
""")
return result["rows"]return: standaard outputreturn rows voor normale Elements, transforms en kleine tot middelgrote snapshots.{"rows": rows, "meta": ...} als de downstream datasource een pure rows-array verwacht.yield: rows stuk voor stuk producerenyield row wanneer je rows kunt produceren zonder eerst alles in een lijst te verzamelen.yield en return rows; kies één outputmodus.rows = list(iterator) als de bron groot kan worden. Je laadt dan de volledige dataset in het geheugen van de Element-runner.yield daarna de outputrow.queryDataSources(..., maxRows=...) of datasourcefilters om de input bewust te begrenzen wanneer je alleen een sample of top-N nodig hebt..to_pandas() alleen als je echt een DataFrame nodig hebt; die stap materialiseert alle opgehaalde rows opnieuw in memory.appendRows, replaceRows en emitProgress; yield is voor het eindresultaat van de entrypoint, niet voor progress-events.def run(params):
# Minder goed: alle rows eerst in memory verzamelen.
rows = list(load_external_rows(params))
return [normalize(row) for row in rows]def run(params):
# Beter voor grote bronnen: per row verwerken.
for row in load_external_rows(params):
yield normalize(row)run(params)def run(params):
limit = int(params.get("limit", 5))
country = params.get("country", "NL")
rows = []
for i in range(limit):
rows.append({
"rank": i + 1,
"country": country,
"value": (i + 1) * 100
})
return rowsdef run(params):
label = params.get("label", "demo")
multiplier = int(params.get("multiplier", 2))
values = params.get("values") or [1, 2, 3]
return [{
"label": label,
"value": value,
"score": value * multiplier
} for value in values]def run(params):
cursor = int(getVar("sync_cursor", 0) or 0)
batch_size = int(params.get("batchSize", 3))
rows = []
for index in range(batch_size):
rows.append({"cursor": cursor + index, "source": "element"})
setVar("sync_cursor", cursor + batch_size)
return rows